Puppet is an open source IT management tool written in Ruby, used for datacenter automation and server management at Google, Twitter, the New York Stock Exchange, and many others. It is primarily maintained by Puppet Labs, which also founded the project. Puppet can manage as few as 2 machines and as many as 50,000, on teams with one system administrator or hundreds.
Puppet is a tool for configuring and maintaining your computers; in its simple configuration language, you explain to Puppet how you want your machines configured, and it changes them as needed to match your specification. As you change that specification over time—such as with package updates, new users, or configuration updates—Puppet will automatically update your machines to match. If they are already configured as desired, then Puppet does nothing.
In general, Puppet does everything it can to use existing system
features to do its work; e.g., on Red Hat it will use yum for packages and
init.d for services, but on OS X it will use dmg for packages and
launchd for services. One of the guiding goals in Puppet is to have
the work it does make sense whether you are looking at Puppet code or
the system itself, so following system standards is critical.
Puppet comes from multiple traditions of other tools. In the open
source world, it is most influenced by CFEngine, which was the first
open source general-purpose configuration tool, and ISconf, whose use
of make for all work inspired the focus on explicit dependencies
throughout the system. In the commercial world, Puppet is a response
to BladeLogic and Opsware (both since acquired by larger companies),
each of which was successful in the market when Puppet was begun, but
each of which was focused on selling to executives at large companies
rather than building great tools directly for system administrators.
Puppet is meant to solve similar problems to these tools, but it is
focused on a very different user.
For a simple example of how to use Puppet, here is a snippet of code that will make sure the secure shell service (SSH) is installed and configured properly:
class ssh {
package { ssh: ensure => installed }
file { "/etc/ssh/sshd_config":
source => 'puppet:///modules/ssh/sshd_config',
ensure => present,
require => Package[ssh]
}
service { sshd:
ensure => running,
require => [File["/etc/ssh/sshd_config"], Package[ssh]]
}
}
This makes sure the package is installed, the file is in place, and
the service is running. Note that we've specified dependencies
between the resources, so that we always perform any work in the right
order. This class could then be associated with any host to apply
this configuration to it. Notice that the building blocks of a Puppet
configuration are structured objects, in this case package, file,
and service. We call these objects resources in Puppet, and
everything in a Puppet configuration comes down to these resources and
the dependencies between them.
A normal Puppet site will have tens or even hundreds of these code
snippets, which we call classes; we store these classes on disk in
files called manifests, and collect them in related groups called
modules. For instance, you might have an ssh module with this
ssh class plus any other related classes, along with modules for
mysql, apache, and sudo.
Most Puppet interactions are via the command line or long-running HTTP services, but there are graphical interfaces for some things such as report processing. Puppet Labs also produces commercial products around Puppet, which tend more toward graphical web-based interfaces.
Puppet's first prototype was written in the summer of 2004, and it was turned into a full-time focus in February of 2005. It was initially designed and written by Luke Kanies, a sysadmin who had a lot of experience writing small tools, but none writing tools greater than 10,000 lines of code. In essence, Luke learned to be a programmer while writing Puppet, and that shows in its architecture in both positive and negative ways.
Puppet was first and foremost built to be a tool for sysadmins, to make their lives easier and allow them to work faster, more efficiently, and with fewer errors. The first key innovation meant to deliver on this was the resources mentioned above, which are Puppet's primitives; they would both be portable across most operating systems and also abstract away implementation detail, allowing the user to focus on outcomes rather than how to achieve them. This set of primitives was implemented in Puppet's Resource Abstraction Layer.
Puppet resources must be unique on a given host. You can only have
one package named "ssh", one service named "sshd", and one file named
"/etc/ssh/sshd_config". This prevents different parts of your
configurations from conflicting with each other, and you find out
about those conflicts very early in the configuration process. We
refer to these resources by their type and title; e.g., Package[ssh]
and Service[sshd]. You can have a package and a service with the same
name because they are different types, but not two packages or
services with the same name.
The second key innovation in Puppet provides the ability to directly specify dependencies between resources. Previous tools focused on the individual work to be done, rather than how the various bits of work were related; Puppet was the first tool to explicitly say that dependencies are a first-class part of your configurations and must be modeled that way. It builds a graph of resources and their dependencies as one of the core data types, and essentially everything in Puppet hangs off of this graph (called a Catalog) and its vertices and edges.
The last major component in Puppet is its configuration language. This language is declarative, and is meant to be more configuration data than full programming—it most resembles Nagios's configuration format, but is also heavily influenced by CFEngine and Ruby.
Beyond the functional components, Puppet has had two guiding principles throughout its development: it should be as simple as possible, always preferring usability even at the expense of capability; and it should be built as a framework first and application second, so that others could build their own applications on Puppet's internals as desired. It was understood that Puppet's framework needed a killer application to be adopted widely, but the framework was always the focus, not the application. Most people think of Puppet as being that application, rather than the framework behind it.
When Puppet's prototype was first built, Luke was essentially a decent Perl programmer with a lot of shell experience and some C experience, mostly working in CFEngine. The odd thing is he had experience building parsers for simple languages, having built two as part of smaller tools and also having rewritten CFEngine's parser from scratch in an effort to make it more maintainable (this code was never submitted to the project, because of small incompatibilities).
A dynamic language was easily decided on for Puppet's implementation, based on much higher developer productivity and time to market, but choosing the language proved difficult. Initial prototypes in Perl went nowhere, so other languages were sought for experimentation. Python was tried, but Luke found the language quite at odds with how he thought about the world. Based on what amounted to a rumor of utility heard from a friend, Luke tried Ruby, and in four hours had built a usable prototype. When Puppet became a full-time effort in 2005 Ruby was a complete unknown, so the decision to stick with it was a big risk, but again programmer productivity was deemed the primary driver in language choice. The major distinguishing feature in Ruby, at least as opposed to Perl, was how easy it was to build non-hierarchical class relationships, but it also mapped very well to Luke's brain, which turned out to be critical.
This chapter is primarily about the architecture of Puppet's implementation (that is, the code that we've used to make Puppet do the things it's supposed to do) but it's worth briefly discussing its application architecture (that is, how the parts communicate), so that the implementation makes some sense.
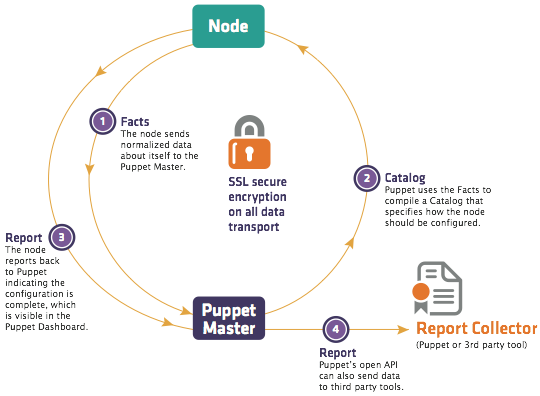
Puppet has been built with two modes in mind: A client/server mode with a central server and agents running on separate hosts, or a serverless mode where a single process does all of the work. To ensure consistency between these modes, Puppet has always had network transparency internally, so that the two modes used the same code paths whether they went over the network or not. Each executable can configure local or remote service access as appropriate, but otherwise they behave identically. Note also that you can use the serverless mode in what amounts to a client/server configuration, by pulling all configuration files to each client and having it parse them directly. This section will focus on the client/server mode, because it's more easily understood as separate components, but keep in mind that this is all true of the serverless mode, too.
One of the defining choices in Puppet's application architecture is that clients should not get access to raw Puppet modules; instead, they get a configuration compiled just for them. This provides multiple benefits: First, you follow the principle of least privilege, in that each host only knows exactly what it needs to know (how it should be configured), but it does not know how any other servers are configured. Second, you can completely separate the rights needed to compile a configuration (which might include access to central data stores) from the need to apply that configuration. Third, you can run hosts in a disconnected mode where they repeatedly apply a configuration with no contact to a central server, which means you remain in compliance even if the server is down or the client is disconnected (such as would be the case in a mobile installation, or when the clients are in a DMZ).
Given this choice, the workflow becomes relatively straightforward:
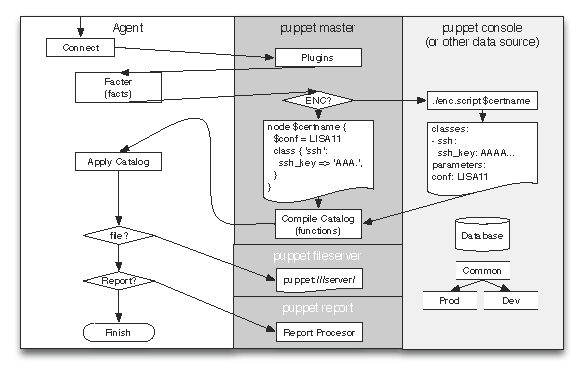
Thus, the agent has access to its own system information, its configuration, and each report it generates. The server has copies of all of this data, plus access to all of the Puppet modules, and any back-end databases and services that might be needed to compile the configuration.
Beyond the components that go into this workflow, which we'll address next, there are many data types that Puppet uses for internal communication. These data types are critical, because they're how all communication is done and they're public types which any other tools can consume or produce.
The most important data types are:
Beyond Facts, Manifests, Catalogs, and Reports, Puppet supports data types for files, certificates (which it uses for authentication), and others.
The first component encountered in a Puppet run is the agent
process. This was traditionally a separate executable called
puppetd, but in version 2.6 we reduced down to one executable so now it
is invoked with puppet agent, akin to how Git works. The agent
has little functionality of its own; it is primarily configuration and
code that implements the client-side aspects of the above-described
workflow.
The next component after the agent is an external tool called Facter, which is a very simple tool used to discover information about the host it is running on. This is data like the operating system, IP address, and host name, but Facter is easily extensible so many organizations add their own plugins to discover custom data. The agent sends the data discovered by Facter to the server, at which point it takes over the workflow.
On the server, the first component encountered is what we call the
External Node Classifier, or ENC. The ENC accepts the host name and
returns a simple data structure containing the high-level
configuration for that host. The ENC is generally a separate service
or application: either another open source project, such as Puppet
Dashboard or Foreman, or integration with existing data stores, such
as LDAP. The purpose of the ENC is to specify what functional classes
a given host belongs to, and what parameters should be used to
configure those classes. For example, a given host might be in the
debian and webserver classes, and have the parameter datacenter
set to atlanta.
Note that as of Puppet 2.7, the ENC is not a required component; users can instead directly specify node configurations in Puppet code. Support for an ENC was added about 2 years after Puppet was launched because we realized that classifying hosts is fundamentally different than configuring them, and it made more sense to split these problems into separate tools than to extend the language to support both facilities. The ENC is always recommended, and at some point soon will become a required component (at which point Puppet will ship with a sufficiently useful one that that requirement will not be a burden).
Once the server receives classification information from the ENC and system information from Facter (via the agent), it bundles all of the information into a Node object and passes it on to the Compiler.
As mentioned above, Puppet has a custom language built for specifying system configurations. Its compiler is really three chunks: A Yacc-style parser generator and a custom lexer; a group of classes used to create our Abstract Syntax Tree (AST); and the Compiler class that handles the interactions of all of these classes and also functions as the API to this part of the system.
The most complicated thing about the compiler is the fact that most Puppet configuration code is lazily loaded on first reference (to reduce both load times and irrelevant logging about missing-but-unneeded dependencies), which means there aren't really explicit calls to load and parse the code.
Puppet's parser uses a normal Yacc-style parser generator built using the open source Racc tool. Unfortunately, there were no open source lexer generators when Puppet was begun, so it uses a custom lexer.
Because we use an AST in Puppet, every statement in the Puppet grammar
evaluates to an instance of a Puppet AST class (e.g.,
Puppet::Parser::AST::Statement), rather than taking action directly,
and these AST instances are collected into a tree as the grammar tree
is reduced. This AST provides a performance benefit when a single
server is compiling configurations for many different nodes, because
we can parse once but compile many times. It also gives us the
opportunity to perform some introspection of the AST, which provides
us information and capability we wouldn't have if parsing operated
directly.
Very few approachable AST examples were available when Puppet was begun, so there has been a lot of evolution in it, and we've arrived at what seems a relatively unique formulation. Rather than creating a single AST for the entire configuration, we create many small ASTs, keyed off their name. For instance, this code:
class ssh {
package { ssh: ensure => present }
}
creates a new AST containing a single
Puppet::Parser::AST::Resource
instance, and stores that AST by the name "ssh" in the hash of all
classes for this particular environment. (I've left out details about
other constructs akin to classes, but they are unnecessary for this
discussion.)
Given the AST and a Node object (from the ENC), the compiler takes the classes specified in the node object (if there are any), looks them up and evaluates them. In the course of this evaluation, the compiler is building up a tree of variable scopes; every class gets its own scope which is attached to the creating scope. This amounts to dynamic scoping in Puppet: if one class includes another class, then the included class can look up variables directly in the including class. This has always been a nightmare, and we have been on the path to getting rid of this capability.
The Scope tree is temporary and is discarded once compiling is done, but the artifact of compiling is also built up gradually over the course of the compilation. We call this artifact a Catalog, but it is just a graph of resources and their relationships. Nothing of the variables, control structures, or function calls survive into the catalog; it's plain data, and can be trivially converted to JSON, YAML, or just about anything else.
During compilation, we create containment relationships; a class "contains" all of the resources that come with that class (e.g., the ssh package above is contained by the ssh class). A class might contain a definition, which itself contains either yet more definitions, or individual resources. A catalog tends to be a very horizontal, disconnected graph: many classes, each no more than a couple of levels deep.
One of the awkward aspects of this graph is that it also contains "dependency" relationships, such as a service requiring a package (maybe because the package installation actually creates the service), but these dependency relationships are actually specified as parameter values on the resources, rather than as edges in the structure of the graph. Our graph class (called SimpleGraph, for historical reasons) does not support having both containment and dependency edges in the same graph, so we have to convert between them for various purposes.
Once the catalog is entirely constructed (assuming there is no failure), it is passed on to the Transaction. In a system with a separate client and server, the Transaction runs on the client, which pulls the Catalog down via HTTP as in Figure 18.2.
Puppet's transaction class provides the framework for actually affecting the system, whereas everything else we've discussed just builds up and passes around objects. Unlike transactions in more common systems such as databases, Puppet transactions do not have behaviors like atomicity.
The transaction performs a relatively straightforward task: walk the
graph in the order specified by the various relationships, and make
sure each resource is in sync. As mentioned above, it has to convert
the graph from containment edges (e.g., Class[ssh] contains
Package[ssh] and Service[sshd]) to dependency edges (e.g.,
Service[sshd] depends on Package[ssh]), and then it does a standard
topological sort of the graph, selecting each resource in turn.
For a given resource, we perform a simple three-step process: retrieve the current state of that resource, compare it to the desired state, and make any changes necessary to fix discrepancies. For instance, given this code:
file { "/etc/motd":
ensure => file,
content => "Welcome to the machine",
mode => 644
}
the transaction checks the content and mode of /etc/motd, and if they don't match the specified state, it will fix either or both of them. If /etc/motd is somehow a directory, then it will back up all of the files in that directory, remove it, and replace it with a file that has the appropriate content and mode.
This process of making changes is actually handled by a simple ResourceHarness class that defines the entire interface between Transaction and Resource. This reduces the number of connections between the classes, and makes it easier to make changes to either independently.
The Transaction class is the heart of getting work done with Puppet, but all of the work is actually done by the Resource Abstraction Layer (RAL), which also happens to be the most interesting component in Puppet, architecturally speaking.
The RAL was the first component created in Puppet and, other than the language, it most clearly defines what the user can do. The job of the RAL is to define what it means to be a resource and how resources can get work done on the system, and Puppet's language is specifically built to specify resources as modeled by the RAL. Because of this, it's also the most important component in the system, and the hardest to change. There are plenty of things we would like to fix in the RAL, and we've made a lot of critical improvements to it over the years (the most crucial being the addition of Providers), but there is still a lot of work to do to the RAL in the long term.
In the Compiler subsystem, we model resources and resource types with
separate classes (named, conveniently, Puppet::Resource and
Puppet::Resource::Type). Our goal is to have these classes also form
the heart of the RAL, but for now these two behaviors (resource and
type) are modeled within a single class, Puppet::Type. (The class is
named poorly because it significantly predates our use of the term
Resource, and at the time we were directly serializing memory
structures when communicating between hosts, so it was actually quite
complicated to change class names.)
When Puppet::Type was first created, it seemed reasonable to put
resource and resource type behaviors in the same class; after all,
resources are just instances of resource types. Over time, however,
it became clear that the relationship between a resource and its
resource type aren't modeled well in a traditional inheritance
structure. Resource types define what parameters a resource can have,
but not whether it accepts parameters (they all do), for instance.
Thus, our base class of Puppet::Type has class-level behaviors that
determine how resource types behave, and instance-level behaviors that
determine how resource instances behave. It additionally has the
responsibility of managing registration and retrieval of resource
types; if you want the "user" type, you call
Puppet::Type.type(:user).
This mix of behaviors makes Puppet::Type quite difficult to maintain.
The whole class is less than 2,000 lines of code, but working at three
levels—resource, resource type, and resource type manager—makes
it convoluted. This is obviously why it's a major target for being
refactored, but it's more plumbing than user-facing, so it's always
been hard to justify effort here rather than directly in features.
Beyond Puppet::Type, there are two major kinds of classes in the RAL,
the most interesting of which are what we call Providers. When the
RAL was first developed, each resource type mixed the definition of a
parameter with code that knew how to manage it. For instance, we
would define the "content" parameter, and then provide a method that
could read the content of a file, and another method that could change
the content:
Puppet::Type.newtype(:file) do
...
newproperty(:content) do
def retrieve
File.read(@resource[:name])
end
def sync
File.open(@resource[:name], "w") { |f| f.print @resource[:content] }
end
end
end
This example is simplified considerably (e.g., we use checksums internally, rather than the full content strings), but you get the idea.
This became impossible to manage as we needed to support multiple varieties of a given resource type. Puppet now supports more than 30 kinds of package management, and it would have been impossible to support all of those within a single Package resource type. Instead, we provide a clean interface between the definition of the resource type—essentially, what the name of the resource type is and what properties it supports—from how you manage that type of resource. Providers define getter and setter methods for all of a resource type's properties, named in obvious ways. For example, this is how a provider of the above property would look:
Puppet::Type.newtype(:file) do
newproperty(:content)
end
Puppet::Type.type(:file).provide(:posix) do
def content
File.read(@resource[:name])
end
def content=(str)
File.open(@resource[:name], "w") { |f| f.print(str) }
end
end
This is a touch more code in the simplest cases, but is much easier to understand and maintain, especially as either the number of properties or number of providers increases.
I said at the beginning of this section that the Transaction doesn't actually affect the system directly, and it instead relies on the RAL for that. Now it's clear that it's the providers that do the actual work. In fact, in general the providers are the only part of Puppet that actually touch the system. The transaction asks for a file's content, and the provider collects it; the transaction specifies that a file's content should be changed, and the provider changes it. Note, however, that the provider never decides to affect the system—the Transaction owns the decisions, and the provider does the work. This gives the Transaction complete control without requiring that it understand anything about files, users, or packages, and this separation is what enables Puppet to have a full simulation mode where we can largely guarantee the system won't be affected.
The second major class type in the RAL is responsible for the parameters themselves. We actually support three kinds of parameters: metaparameters, which affect all resource types (e.g., whether you should run in simulation mode); parameters, which are values that aren't reflected on disk (e.g., whether you should follow links in files); and properties, which model aspects of the resource that you can change on disk (e.g., a file's content, or whether a service is running). The difference between properties and parameters is especially confusing to people, but if you just think of properties as having getter and setter methods in the providers, it's relatively straightforward.
As the transaction walks the graph and uses the RAL to change the system's configuration, it progressively builds a report. This report largely consists of the events generated by changes to the system. These events, in turn, are comprehensive reflections of what work was done: they retain a timestamp the resource changed, the previous value, the new value, any message generated, and whether the change succeeded or failed (or was in simulation mode).
The events are wrapped in a ResourceStatus object that maps to each resource. Thus, for a given Transaction, you know all of the resources that are run, and you know any changes that happen, along with all of the metadata you might need about those changes.
Once the transaction is complete, some basic metrics are calculated and stored in the report, and then it is sent off to the server (if configured). With the report sent, the configuration process is complete, and the agent goes back to sleep or the process just ends.
Now that we have a thorough understanding of what Puppet does and how, it's worth spending a little time on the pieces that don't show up as capabilities but are still critical to getting the job done.
One of the great things about Puppet is that it is very extensible. There are at least 12 different kinds of extensibility in Puppet, and most of these are meant to be usable by just about anyone. For example, you can create custom plugins for these areas:
However, Puppet's distributed nature means that agents need a way to retrieve and load new plugins. Thus, at the start of every Puppet run, the first thing we do is download all plugins that the server has available. These might include new resource types or providers, new facts, or even new report processors.
This makes it possible to heavily upgrade Puppet agents without ever changing the core Puppet packages. This is especially useful for highly customized Puppet installations.
You've probably detected by now that we have a tradition of bad class names in Puppet, and according to most people, this one takes the cake. The Indirector is a relatively standard Inversion of Control framework with significant extensibility. Inversion of Control systems allow you to separate development of functionality from how you control which functionality you use. In Puppet's case, this allows us to have many plugins that provide very different functionality, such as reaching the compiler via HTTP or loading it in-process, and switch between them with a small configuration change rather than a code change. In other words, Puppet's Indirector is basically an implementation of a service locator, as described on the Wikipedia page for "Inversion of Control". All of the hand-offs from one class to another go through the Indirector, via a standard REST-like interface (e.g., we support find, search, save, and destroy as methods), and switching Puppet from serverless to client/server is largely a question of configuring the agent to use an HTTP endpoint for retrieving catalogs, rather than using a compiler endpoint.
Because it is an Inversion of Control framework where configuration is stringently separated from the code paths, this class can also be difficult to understand, especially when you're debugging why a given code path was used.
Puppet's prototype was written in the summer of 2004, when the big networking question was whether to use XMLRPC or SOAP. We chose XMLRPC, and it worked fine but had most of the problems everyone else had: it didn't encourage standard interfaces between components, and it tended to get overcomplicated very quickly as a result. We also had significant memory problems, because the encoding needed for XMLRPC resulted in every object appearing at least twice in memory, which quickly gets expensive for large files.
For our 0.25 release (begun in 2008), we began the process of switching all networking to a REST-like model, but we chose a much more complicated route than just changing out the networking. We developed the Indirector as the standard framework for inter-component communication, and built REST endpoints as just one option. It took two releases to fully support REST, and we have not quite finished converting to using JSON (instead of YAML) for all serialization. We undertook switching to JSON for two major reasons: first, YAML processing Ruby is painfully slow, and pure Ruby processing of JSON is a lot faster; second, most of the web seems to be moving to JSON, and it tends to be implemented more portably than YAML. Certainly in the case of Puppet, the first use of YAML was not portable across languages, and was often not portable across different versions of Puppet, because it was essentially serialization of internal Ruby objects.
Our next major release of Puppet will finally remove all of the XMLRPC support.
In terms of implementation, we're proudest of the various kinds of separation that exist in Puppet: the language is completely separate from the RAL, the Transaction cannot directly touch the system, and the RAL can't decide to do work on its own. This gives the application developer a lot of control over application workflow, along with a lot of access to information about what is happening and why.
Puppet's extensibility and configurability are also major assets, because anyone can build on top of Puppet quite easily without having to hack the core. We've always built our own capabilities on the same interfaces we recommend our users use.
Puppet's simplicity and ease of use have always been its major draw. It's still too difficult to get running, but it's miles easier than any of the other tools on the market. This simplicity comes with a lot of engineering costs, especially in the form of maintenance and extra design work, but it's worth it to allow users to focus on their problems instead of the tool.
Puppet's configurability is a real feature, but we took it a bit too far. There are too many ways you can wire Puppet together, and it's too easy to build a workflow on top of Puppet that will make you miserable. One of our major near-term goals is to dramatically reduce the knobs you can turn in a Puppet configuration, so the user cannot so easily configure it poorly, and so we can more easily upgrade it over time without worrying about obscure edge cases.
We also just generally changed too slowly. There are major refactors we've been wanting to do for years but have never quite tackled. This has meant a more stable system for our users in the short term, but also a more difficult-to-maintain system, and one that's much harder to contribute to.
Lastly, it took us too long to realize that our goals of simplicity were best expressed in the language of design. Once we began speaking about design rather than just simplicity, we acquired a much better framework for making decisions about adding or removing features, with a better means of communicating the reasoning behind those decisions.
Puppet is both a simple system and a complex one. It has many moving parts, but they're wired together quite loosely, and each of them has changed pretty dramatically since its founding in 2005. It is a framework that can be used for all manner of configuration problems, but as an application it is simple and approachable.
Our future success rests on that framework becoming more solid and more simple, and that application staying approachable while it gains capability.