Since their initial adoption, EMR (electronic medical record) systems have attempted to bridge the gap between the physical and digital worlds of patient care. Governments in countries around the world have attempted to come up with a solution that enables better care for patients at a lower cost while reducing the paper trail that medicine typically generates. Many governments have been very successful in their attempts to create such a system—some, like that of the Canadian province of Ontario, have not (some may remember the so-called "eHealth Scandal" in Ontario that, according to the Auditor General, cost taxpayers $1 billion CAD).
An EMR permits the digitization of a patient chart, and when used properly should make it easier for a physician to deliver care. A good system should provide a physician a bird's eye view of a patient's current and ongoing conditions, their prescription history, their recent lab results, history of their previous visits, and so on. OSCAR (Open Source Clinical Application Resource), an approximately ten-year-old project of McMaster University in Hamilton, Ontario, Canada, is the open source community's attempt to provide such a system to physicians at low or no cost.
OSCAR has many subsystems that provide functionality on a component-by-component basis. For example, oscarEncounter provides an interface for interacting with a patient's chart directly; Rx3 is a prescription module that checks for allergies and drug interactions automatically and allows a physician to directly fax a prescription to a pharmacy from the UI; the Integrator is a component to enable data sharing between multiple compatible EMRs. All of these separate components come together to build the typical OSCAR user experience.
OSCAR won't be for every physician; for example, a specialist may not find all the features of the system useful, and it is not easily customizable. However, it offers a complete set of features for a general physician interacting with patients on a day-to-day basis.
In addition, OSCAR is CMS 3.0 certified (and has applied for CMS 4.0 certification)—which allows physicians to receive funding for installing it in their clinic (see EMR Advisor for details). Receiving CMS certification involves passing a set of requirements from the Government of Ontario and paying a fee.
This chapter will discuss the architecture of OSCAR in fairly general terms, describing the hierarchy, major components, and most importantly the impact that past decisions have made on the project. As a conclusion and to wrap up, there will be a discussion on how OSCAR might have been designed today if there was an opportunity to do so.
As a Tomcat web application, OSCAR generally follows the typical model-view-controller design pattern. This means that the model code (Data Access Objects, or DAOs) is separate from the controller code (servlets) and those are separated from the views (Java Server Pages, or JSPs). The most significant difference between the two is that servlets are classes and JSPs are HTML pages marked up with Java code. Data gets placed into memory when a servlet executes and the JSP reads that same data, usually done via reads and writes to the attributes of the request object. Just about every JSP page in OSCAR has this kind of design.
I mentioned that OSCAR is a fairly old project. This has implications
for how effectively the MVC pattern has been applied. In short, there
are sections of the code that completely disregard the pattern as they
were written before tighter enforcement of the MVC pattern began. Some
of the most common features are written this way; for example,
performing many actions related to demographics (patient records) are
done via the demographiccontrol.jsp file—this includes
creating patients and updating their data.
OSCAR's age is a hurdle for tackling many of the problems that are facing the source tree today. Indeed, there has been significant effort made to improve the situation, including enforcing design rules via a code review process. This is an approach that the community at present has decided will allow better collaboration in the future, and will prevent poor code from becoming part of the code base, which has been a problem in the past.
This is by no means a restriction on how we could design parts of the system now; it does, however, make it more complicated when deciding to fix bugs in a dated part of OSCAR. Do you, as somebody tasked to fix a bug in the Demographic Creation function, fix the bug with code in the same style as it currently exists? Or do you re-write the module completely so that it closely follows the MVC design pattern?
As developers we must carefully weigh our options in situations like those. There is no guarantee that if you re-architect a part of the system you will not create new bugs, and when patient data is on the line, we must make the decision carefully.
A CVS repository was used for much of OSCAR's life. Commits weren't often checked for consistency and it was possible to commit code that could break the build. It was tough for developers to keep up with changes—especially new developers joining the project late in its lifecycle. A new developer could see something that they would want to change, make the change, and get it into the source branch several weeks before anybody would notice that something significant had been modified (this was especially prevalent during long holidays, such as Christmas break, when not many people were watching the source tree).
Things have changed; OSCAR's source tree is now controlled by git. Any commits to the main branch have to pass code-style checking and unit testing, successfully compile, and be code reviewed by the developers. (Much of this is handled by the combination of Hudson, a continuous integration server and Gerrit, a code review tool.) The project has become much more tightly controlled. Many or all of the issues caused by poor handling of the source tree have been solved.
When looking through the OSCAR source, you may notice that there are
many different ways to access the database: you can use a direct
connection to the database via a class called DBHandler, use a
legacy Hibernate model, or use a generic JPA model. As new and easier
database access models became available, they were integrated into
OSCAR. The result is that there is now a slightly noisy picture of how
OSCAR interacts with data in MySQL, and the differences between the
three types of data access methods are best described with examples.
The EForm system allows users to create their own forms to attach to patient records—this feature is usually used to replace a paper-based form with a digital version. On each creation of a form of a particular type, the form's template file is loaded; then the data in the form is stored in the database for each instance. Each instance is attached to a patient record.
EForms allow you to pull in certain types of data from a patient chart
or other area of the system via free-form SQL queries (which are
defined in a file called apconfig.xml). This can be extremely
useful, as a form can load and then immediately be populated with
demographic or other relevant information without intervention from
the user; for example, you wouldn't have to type in a patient's name,
age, date of birth, hometown, phone number, or the last note that was
recorded for that patient.
A design decision was made, when originally developing the EForm module,
to use raw database queries to populate a POJO (plain-old Java object)
called EForm in the controller that is then passed to the view
layer to display data on the screen, sort of like a JavaBean. Using a
POJO in this case is actually closer in design to the Hibernate or JPA
architecture, as I'll discuss in the next sections.
All of the functionality regarding saving EForm instances and
templates is done via raw SQL queries run through the DBHandler
class. Ultimately, DBHandler is a wrapper for a simple JDBC
object and does not scrutinize a query before sending it to the SQL
server. It should be added here that DBHandler is a potential
security flaw as it allows unchecked SQL to be sent to the server. Any
class that uses
DBHandler must implement its own checking to make sure that SQL
injection doesn't occur.
Depending on the type of application you're writing, direct access of a database is sometimes fine. In certain cases, it can even speed development up. Using this method to access the database doesn't conform to the model-view-controller design pattern, though: if you're going to change your database structure (the model), you have to change the SQL query elsewhere (in the controller). Sometimes, adding certain columns or changing their type in OSCAR's database tables requires this kind of invasive procedure just to implement small features.
It may not surprise you to find out that the DBHandler object
is one of the oldest pieces of code still intact in the source. I
personally don't know where it originated from but I consider it to be
the most "primitive" of database access types that exist in the
OSCAR source. No new code is permitted to use this class, and if
code is committed that uses it, the commit will be
rejected automatically.
A demographic record contains general metadata about a patient; for example, their name, age, address, language, and sex; consider it to be the result of an intake form that a patient fills out during their first visit to a doctor. All of this data is retrieved and displayed as part of OSCAR's Master Record for a specific demographic.
Using Hibernate to access the database is far safer than
using DBHandler. For one, you have to explicitly define which
columns match to which fields in your model object (in this case, the
Demographic class). If you want to perform complex joins, they have to
be done as prepared statements. Finally, you will only ever receive an
object of the type you ask for when performing a query, which is very
convenient.
The process of working with a Hibernate-style DAO and Model pair is
quite simple. In the case of the Demographic object, there's a file
called Demographic.hbm.xml that describes the mapping between object
field and database column. The file describes which table to look at
and what type of object to return. When OSCAR starts, this file will
be read and a sanity check occurs to make sure that this kind of
mapping can actually be made (server startup fails if it can't). Once
running, you grab an instance of the DemographicDao object and run
queries against it.
The best part about using Hibernate over DBHandler is that all
of the queries to the server are prepared statements. This restricts
you from running free-form SQL during runtime, but it also prevents
any type of SQL injection attack. Hibernate will often build large
queries to grab the data, and it doesn't always perform in an
extremely efficient way.
In the previous section I mentioned an example of the EForm module
using DBHandler to populate a POJO. This is the next logical
step to preventing that kind of code from being written. If the model
has to change, only the .hbm.xml file and the model class have
to change (a new field and getter/setter for the new column), and
doing so won't impact the rest of the application.
While newer than DBHandler, the Hibernate method is also
starting to show its age. It's not always convenient to use and
requires a big configuration file for each table you want to
access. Setting up a new object pair takes time and if you do it
incorrectly OSCAR won't even start. For this reason, nobody should be
writing new code that uses pure Hibernate, either. Instead, generic
JPA is being embraced in new development.
The newest form of database access is done via generic JPA. If the OSCAR project decided to switch from Hibernate to another database access API, conforming to the JPA standard for DAOs and Model objects would make it very easy to migrate. Unfortunately, because this is so "new" to the OSCAR project, there are almost no areas of the system that actually use this method to get data.
In any case, let me explain how it works. Instead of a .hbm.xml
file, you add annotations to your Model and DAO objects. These
annotations describe the table to look in, column mappings for fields,
and join queries. Everything is contained inside the two files and
nothing else is necessary for their operation. Hibernate still runs
behind the scenes, though, in actually retrieving the data from the
database.
All of the Integrator's models are written using JPA—and they are pretty good examples of both the new style of database access as well as demonstrating that as a new technology to be implemented into OSCAR, it hasn't been used in very many places yet. The Integrator is a relatively new addition to the source. It makes quite a lot of sense to use this new data access model as opposed to Hibernate.
Touching on a now-common theme in this section of the chapter, the annotated POJOs that JPA uses allow for a far more streamlined experience. For example, during the Integrator's build process, an SQL file is created that sets up all of the tables for you—an enormously useful thing to have. With that ability, it's impossible to create mismatching tables and model objects (as you can do with any other type of database access method) and you never have to worry about naming of columns and tables. There are no direct SQL queries, so it's not possible to create SQL injection attacks. In short, it "just works".
The way that JPA works can be considered to be fairly similar to the way that ActiveRecord works in Ruby on Rails. The model class defines the data type and the database stores it; what happens in between that—getting data in and out—is not up to the user.
Both Hibernate and JPA offer some significant benefits in typical use cases. For simple retrieval and storage, they really cut time out of development and debugging.
However, that doesn't mean that their implementation into OSCAR has been without issue. Because the user doesn't define the SQL between the database and the POJO referencing a specific row, Hibernate gets to choose the best way to do it. The "best way" can manifest itself in a couple of ways: Hibernate can choose to just retrieve the simple data from the row, or it can perform a join and retrieve a lot of information at once. Sometimes these joins get out of hand.
Here's another example: The casemgmt_note table
stores all patient notes. Each note object stores lots of metadata
about the note—but it also stores a list of all of the issues that
the note deals with (issues can be things like, "smoking cessation"
or "diabetes", which describe the contents of the note).
The list of issues is represented in the note object as a
List<CaseManagementIssue>. In order to get that list,
the casemgmt_note table is joined with the casemgmt_issue_notes
table (which acts as a mapping table) and finally the
casemgmt_issue table.
When you want to write a custom query in Hibernate, which this situation requires, you don't write standard SQL—you write HQL (Hibernate Query Language) that is then translated to SQL (by inserting internal column names for all the fields to be selected) before parameters are inserted and the query is sent to the database server. In this specific case, the query was written with basic joins with no join columns—meaning that when the query was eventually translated to SQL, it was so large that it wasn't immediately obvious what the query was gathering. Additionally, in almost all cases, this never created a large enough temporary table for it to matter. For most users, this query actually runs quickly enough that it's not noticeable. However, this query is unbelievably inefficient.
Let's step back for a second. When you perform a join on two tables, the server has to create a temporary table in memory. In the most generic type of joins, the number of rows is equal to the number of rows in the first table multiplied by the number of rows in the second table. So if your table has 500,000 rows, and you join it with a table that has 10,000,000 rows, you've just created a 5×1012 row temporary table in memory, which the select statement is then run against and that temporary table is discarded.
In one extreme case that we ran into, the join across
three tables caused a temporary table to be created that was
around 7×1012 rows in length, of which about
1000 rows were eventually selected. This operation took about 5
minutes and locked the casemgmt_note table while it was running.
The problem was solved, eventually, through the use of a prepared statement that restricted the scope of the first table before joining with the other two. The newer, far more efficient query brought the number of rows to select down to a very manageable 300,000 and enormously improved performance of the notes retrieval operation (down to about 0.1 seconds to perform the same select statement).
The moral of the story is simply that while Hibernate does a fairly
good job, unless the join is very explicitly defined and controlled
(either in the .hbm.xml file or a join annotation in the object class
for a JPA model), it can very quickly get out of control. Dealing with
objects instead of SQL queries requires you to leave the actual
implementation of the query up to the database access library and only
really allows you to control definition. Unless you're careful with
how you define things, it can all fall apart under extreme
conditions. Furthermore, if you're a database programmer with lots of
SQL knowledge, it won't really help much when designing a
JPA-enabled class, and it removes some of the control that you would
have if you were writing an SQL statement manually. Ultimately, a good
knowledge of both SQL and JPA annotations and how they affect
queries is required.
CAISI (Client Access to Integrated Services and Information) was originally a standalone product—a fork of OSCAR—to help manage homeless shelters in Toronto. A decision was eventually made to merge the code from CAISI into the main source branch. The original CAISI project may no longer exist, but what it gave to OSCAR is very important: its permission model.
The permissions model in OSCAR is extremely powerful and can be used to create just about as many roles and permission sets as possible. Providers belong to programs (as staff) where they have a specific role. Each program takes place at a facility. Each role has a description (for example, "doctor", "nurse", "social worker", and so on) and a set of attached global permissions. The permissions are written in a format that makes them very easy to understand: "read nurse notes" may be a permission that a doctor role may have, but the nurse role may not have the "read doctor notes" permission.
This format may be easy to understand, but under the hood it requires quite a bit of heavy lifting to actually check for these types of permissions. The name of the role that the current provider has is checked against its list of permissions for a match with the action that they are trying to perform. For example, a provider attempting to read a doctor's notes would cause "read doctor notes" to be checked for each and every note written by a doctor.
Another problem is the reliance on English for permission definition. Anybody using OSCAR in a language other than English would still need to write their permissions in a format such as "read [role] notes", using the English words "read", "write", "notes", and so on.
CAISI's permission model is a significant part of OSCAR, but it's not the only model in place. Before CAISI was implemented, another role-based (but not program-based) system was developed and is still in use in many parts of the system today.
For this second system, providers are assigned one or many roles (for example, "doctor", "nurse", "admin", and so on). They can be assigned as many roles as necessary—the roles' permissions stack on top of each other. These permissions are generally used for restricting access to parts of the system, as opposed to CAISI's permissions which restrict access to certain pieces of data on a patient's chart. For example, a user has to have the "_admin" "read" permission on a role that they have assigned to them to be able to access the Admin panel. Having the "read" permission will exempt them from being able to perform administrative tasks, however. They'll need the "write" permission as well for that.
Both of these systems accomplish roughly the same goal; it's due to CAISI's merge later in the project lifecycle that they both exist. They don't always exist happily together, so in reality it can be a lot easier to just focus on using one for day-to-day operations of OSCAR. You can generally date code in OSCAR by knowing which permissions model preceded which other permissions model: Provider Type then Provider Roles then CAISI Programs/Roles
The oldest type of permissions model, "Provider Type", is so dated that it's actually not used in most parts of the system and is in fact defaulted to "doctor" during new provider creation—having it as any other value (such as "receptionist") causes significant issues throughout the system. It's easier and more fine-grained to control permissions via Provider Roles instead.
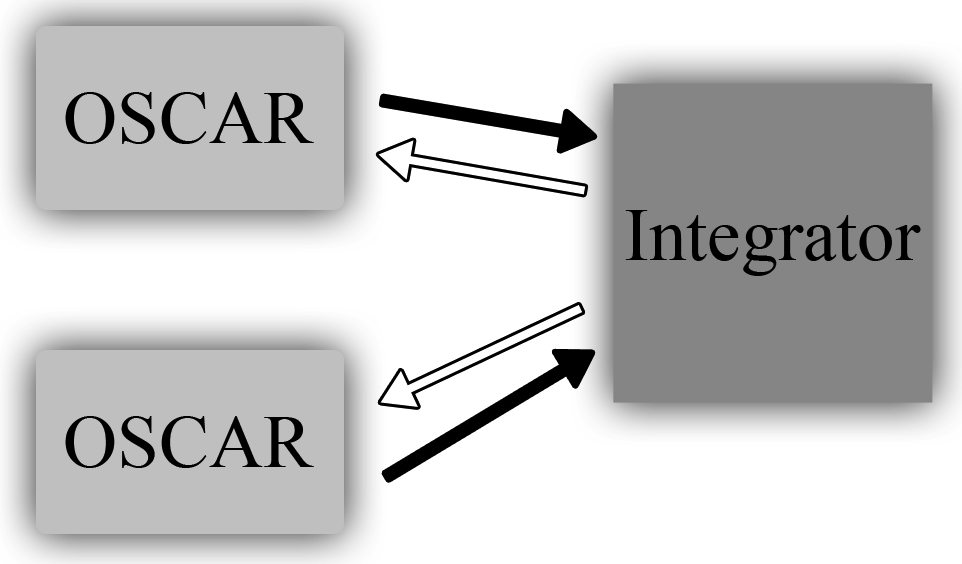
OSCAR's Integrator component is a separate web application that independent OSCAR instances use to exchange patient, program and provider information over a secure link. It can be optionally installed as a component for an installation in an environment such as a LHN (Local Health Network) or a hospital. The easiest way to describe the Integrator is as a temporary storage facility.
Consider the following use case and argument for use of the Integrator: in Hospital X, there is an ENT (ear, nose, and throat) clinic as well as an endocrinology clinic. If an ENT doctor refers their patient to an endocrinologist upstairs, they may be required to send along patient history and records. This is inconvenient and generates more paper than is necessary—perhaps the patient is only seeing the endocrinologist once. By using the Integrator, the patient's data can be accessed on the endocrinologist's EMR, and access to the contents of the patient's chart can be revoked after the visit.
A more extreme example: if an unconscious man shows up in an ER with nothing but his health card, because the home clinic and the hospital's system are connected via the Integrator, the man's record can be pulled and it can be very quickly realized that he has been prescribed the blood thinner warfarin. Ultimately, information retrieval like this is what an EMR like OSCAR paired with the Integrator can achieve.
The Integrator is available in source code form only, which requires the user to retrieve and build it manually. Like OSCAR, it runs on a standard installation of Tomcat with MySQL.
When the URL where the Integrator lives is accessed, it doesn't appear to display anything useful. This component is almost purely a web service; OSCAR communicates via POST and GET requests to the Integrator URL.
As an independently developed project (initially as part of the CAISI project), the Integrator is fairly strict in adhering to the MVC design pattern. The original developers have done an excellent job of setting it up with very clearly defined lines between the models, views, and controllers. The most recently implemented type of database access layer that I mentioned earlier—generic JPA—is the only such layer in the project. (As an interesting side note: because the entire project is properly set up with JPA annotations on all the model classes, an SQL script is created at build time that can be used to initialize the structure of the database; the Integrator, therefore, doesn't ship with a stand-alone SQL script.)
Communication is handled via web service calls described in WSDL XML files that are available on the server. A client could query the Integrator to find out what kind of functions are available and adapt to it. This really means that the Integrator is compatible with any kind of EMR that somebody decides to write a client for; the data format is generic enough that it could easily be mapped to local types.
For OSCAR, though, a client library is built and included in the main source tree, for simplicity's sake. That library only ever needs to be updated if new functions become available on the Integrator. A bug fix on the Integrator doesn't require an update of that file.
Data for the Integrator comes in from all of the connected EMRs at scheduled times and, once there, another EMR can request that data. None of the data on the Integrator is stored permanently, though—its database could be erased and it could be rebuilt from the client data.
The dataset sent is configured individually at each OSCAR instance which is connected to a particular Integrator, and except in situations where the entire patient database has to be sent to the Integrator server, only patient records that have been viewed since the previous push to the server are sent. The process isn't exactly like delta patching, but it's close.
Let me go into a little more detail about how the Integrator works with an example: a remote clinic seeing another clinic's patient. When that clinic wants to access the patient's record, the clinics first have to have been connected to the same Integrator server. The receptionist can search the Integrator for the remote patient (by name and optionally date of birth or sex) and find their record stored on the server. They initiate the copy of a limited set of the patient's demographic information and then double-check with the patient to make sure that they consent to the retrieval of their record by completing a consent form. Once completed, the Integrator server will deliver whatever information the Integrator knows about that patient—notes, prescriptions, allergies, vaccinations, documents, and so on. This data is cached locally so that the local OSCAR doesn't have to send a request to the Integrator every time it wants to see this data, but the local cache expires every hour.
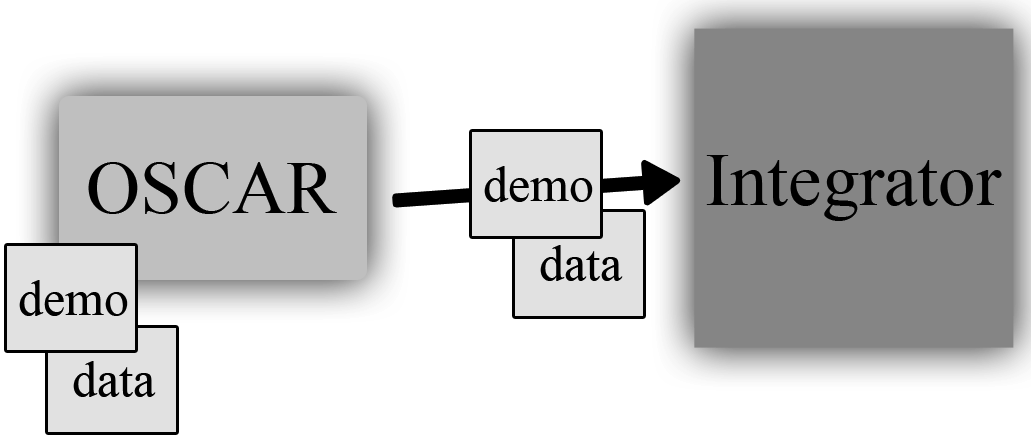
After the initial setup of a remote patient by copying their demographic data to the local OSCAR, that patient is set up as any other on the system. All of the remote data that is retrieved from the Integrator is marked as such (and the clinic from which it came from is noted), but it's only temporarily cached on the local OSCAR. Any local data that is recorded is recorded just like any other patient data—to the patient record, and sent to the Integrator—but not permanently stored on any remote machine.
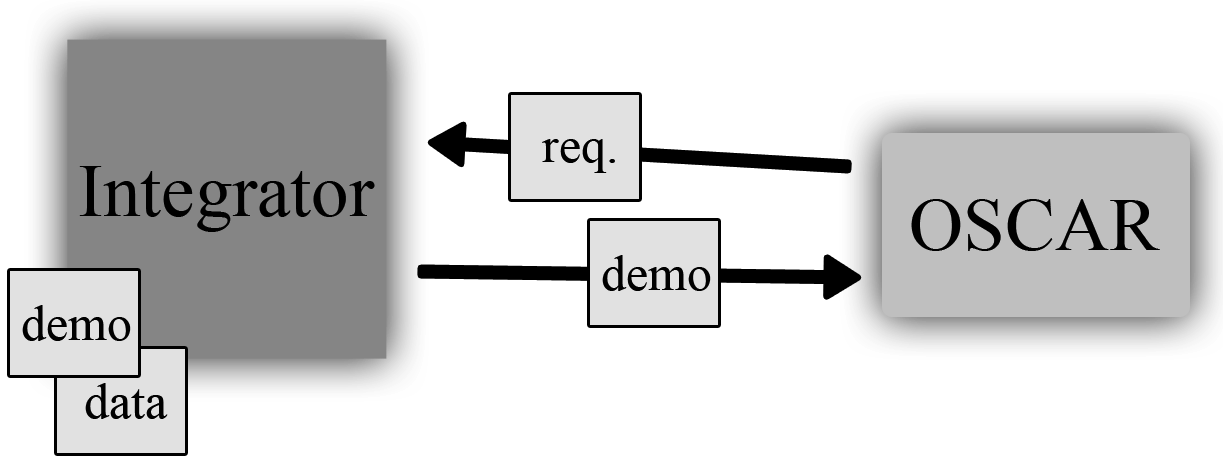
This has a very important implication, especially for patient consent and how that factors into the design of the Integrator. Let's say that a patient sees a remote physician and is fine with them having access to their record, but only temporarily. After their visit, they can revoke the consent for that clinic to be able to view that patient's record and the next time that clinic opens the patient's chart there won't be any data there (with the exception of any data that was locally recorded). This ultimately gives control over how and when a record is viewed directly to the patient and is similar to walking into a clinic carrying a copy of your paper chart. They can see the chart while they're interacting with you, but you take it home with you when you leave.
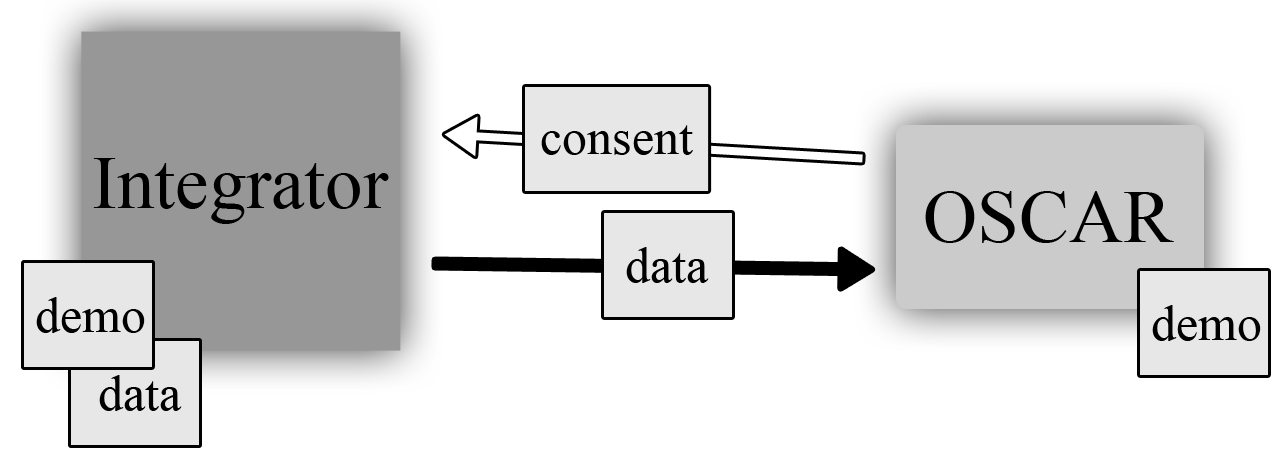
Another very important ability is for physicians to decide what kinds of data they want to share with the other connected clinics via their Integrator server. A clinic can choose to share all of a demographic record or only parts of it, such as notes but not documents, allergies but not prescriptions, and so on. Ultimately it's up to the group of physicians who set up the Integrator server to decide what kinds of data they're comfortable with sharing with each other.
As I mentioned before, the Integrator is only a temporary storage warehouse and no data is ever stored permanently there. This is another very important decision that was made during development; it allows clinics to back out of sharing any and all data via the Integrator very easily—and in fact if necessary the entire Integrator database can be wiped. If the database is wiped, no user of a client will ever notice because the data will be accurately reconstructed from the original data on all of the various connected clients. An implication is that the OSCAR provider needs to trust the Integrator provider to have wiped the database when they say so—it is therefore best to deploy an Integrator to a group of physicians already in a legal organization such as a Family Health Organization or Family Health Team; the Integrator server would be housed at one of these physician's clinics.
The Integrator's client libraries are built via wsdl2java, which
creates a set of classes representing the appropriate data types the
web service communicates in. There are classes for each data type as
well as classes representing keys for each of these data types.
It's outside the scope of this chapter to describe how to build the Integrator's client library. What's important to know is that once the library is built, it must be included with the rest of the JARs in OSCAR. This JAR contains everything necessary to set up the Integrator connection and access all of the data types that the Integrator server will return to OSCAR, such as CachedDemographic, CachedDemographicNote, and CachedProvider, among many others. In addition to the data types that are returned, there are "WS" classes that are used for the retrieval of such lists of data in the first place—the most frequently used being DemographicWs.
Dealing with the Integrator data can sometimes be a little
tricky. OSCAR doesn't have anything truly built-in to handle this kind
of data, so what usually happens is when retrieving a certain
kind of patient data (for example, notes for a patient's chart) the
Integrator client is asked to retrieve data from the server. That data
is then manually transformed into a local class representing that data
(in the case of notes, it's a CaseManagementNote). A Boolean flag is
set inside the class to indicate that it's a piece of remote content
and that is used to change how the data is displayed to the user on
the screen. On the opposite end, CaisiIntegratorUpdateTask handles taking local
OSCAR data, converting it into the Integrator's data format, and then
sending that data to the Integrator server.
This design may not be as efficient or as clean as possible, but it does enable older parts of the system to become "compatible" with Integrator-delivered data without much modification. In addition, keeping the view as simple as possible by referring to only one type of class improves the readability of the JSP file and makes it easier to debug in the event of an error.
As you can probably imagine, OSCAR has its share of issues when it comes to overall design. It does, however, provide a complete feature set that most users will find no issues with. That's ultimately the goal of the project: provide a good solution that works in most situations.
I can't speak for the entire OSCAR community, so this section will be highly subjective and from my point of view. I feel that there are some important takeaways from an architectural discussion about the project.
First, it's clear that poor source control in the past has caused the architecture of the system to become highly chaotic in parts, especially in areas where the controllers and the views blend together. The way that the project was run in the past didn't prevent this from happening, but the process has changed since and hopefully we won't have to deal with such a problem again.
Next, because the project is so old, it's difficult to upgrade (or even change) libraries without causing significant disruption throughout the code base. That's exactly what has happened, though. I often find it difficult to figure out what's necessary and what isn't when I'm looking in the library folder. In addition to that, sometimes when libraries undergo major upgrades they break backwards compatibility (changing package names is a common offense). There are often several libraries included with OSCAR that all accomplish the same task—this goes back to poor source control, but also the fact that that there has been no list or documentation describing which library is required by which component.
Additionally, OSCAR is a little inflexible when it comes to adding new features to existing subsystems. For example, if you want to add a new box to the E-Chart, you'll have to create a new JSP page and a new servlet, modify the layout of the E-Chart (in a few places), and modify the configuration file of the application so that your servlet can load.
Next, due to the lack of documentation, sometimes it is nearly impossible to figure out how a part of the system works—the original contributor may not even be part of the project anymore—and often the only tool you have to figure it out is a debugger. As a project of this age, this is costing the community the potential for new contributors to get involved. However, it's something that, as a collaborative effort, the community is working on.
Finally, OSCAR is a repository for medical information and its
security is compromised by the inclusion of the DBHandler class
(discussed in a previous section). I personally feel that freeform
database queries that accept parameters should never be acceptable in
an EMR because it's so easy to perform SQL injection attacks. While
it's good that no new code is permitted that uses this class, it
should be a priority of the development team to remove all instances
of its use.
All of that may sound like some harsh criticism of the project. In the past, all of these problems have been significant and, like I said, prevent the community from growing as the barrier to entry is so high. This is something that is changing, so in the future, these issues won't be so much of a hindrance.
In looking back over the project's history (and especially over the past few versions) we can come up with a better design for how the application would be built. The system still has to provide a base level of functionality (mandated by the Ontario government for certification as an EMR), so that all has to be baked in by default. But if OSCAR were to be redesigned today, it should be designed in a truly modular fashion that would allow modules to be treated as plugins; if you didn't like the default E-Form module, you could write your own (or even another module entirely). It should be able to speak to more systems (or more systems should be able to speak to it), including the medical hardware that you see in increasing use throughout the industry, such as devices for measuring visual acuity. This also means that it would be easy to adapt OSCAR to the requirements of local and federal governments around the world for storing medical data. Since every region has a different set of laws and requirements, this kind of design would be crucial for making sure that OSCAR develops a worldwide userbase.
I also believe that security should be the most important feature of all. An EMR is only as secure as its least secure component, so there should be focus on abstracting away as much data access as possible from the application so that it stores and retrieves data in a sandbox-style environment through a main data access layer API that has been audited by a third-party and found to be adequate for storing medical information. Other EMRs can hide behind obscurity and proprietary code as a security measure (which isn't really a security measure at all), but being open source, OSCAR should lead the charge with better data protection.
I stand firmly as a believer in the OSCAR project. We have hundreds of users that we know about (and the many hundreds that we don't), and we receive valuable feedback from the physicians who are interacting with our project on a daily basis. Through the development of new processes and new features, we hope to grow the installed base and to support users from other regions. It is our intention to make sure that what we deliver is something that improves the lives of the physicians who use OSCAR as well as the lives of their patients, by creating better tools to help manage healthcare.