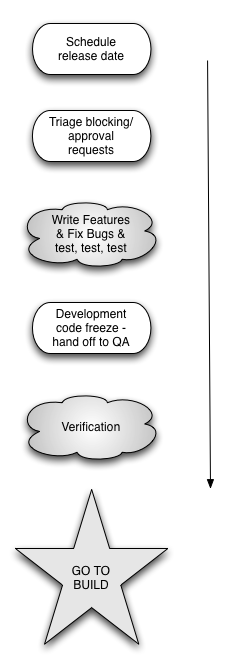
Recently, the Mozilla Release Engineering team has made numerous advances in release automation for Firefox. We have reduced the requirements for human involvement during signing and sending notices to stakeholders, and have automated many other small manual steps, because each manual step in the process is an opportunity for human error. While what we have now isn't perfect, we're always striving to streamline and automate our release process. Our final goal is to be able to push a button and walk away; minimal human intervention will eliminate many of the headaches and do-overs we experienced with our older part-manual, part-automated release processes. In this chapter, we will explore and explain the scripts and infrastructure decisions that comprise the complete Firefox rapid release system, as of Firefox 10.
You'll follow the system from the perspective of a release-worthy Mercurial changeset as it is turned into a release candidate—and then a public release—available to over 450 million daily users worldwide. We'll start with builds and code signing, then customized partner and localization repacks, the QA process, and how we generate updates for every supported version, platform and localization. Each of these steps must be completed before the release can be pushed out to Mozilla Community's network of mirrors which provide the downloads to our users.
We'll look at some of the decisions that have been made to improve this process; for example, our sanity-checking script that helps eliminate much of what used to be vulnerable to human error; our automated signing script; our integration of mobile releases into the desktop release process; patcher, where updates are created; and AUS (Application Update Service), where updates are served to our users across multiple versions of the software.
This chapter describes the mechanics of how we generate release builds for Firefox. Most of this chapter details the significant steps that occur in a release process once the builds start, but there is also plenty of complex cross-group communication to deal with before Release Engineering even starts to generate release builds, so let's start there.
When we started on the project to improve Mozilla's release process, we began with the premise that the more popular Firefox became, the more users we would have, and the more attractive a target Firefox would become to blackhat hackers looking for security vulnerabilities to exploit. Also, the more popular Firefox became, the more users we would have to protect from a newly discovered security vulnerability, so the more important it would be to be able to deliver a security fix as quickly as possible. We even have a term for this: a "chemspill" release (short for "chemical spill"). Instead of being surprised by the occasional need for a chemspill release in between our regularly scheduled releases, we decided to plan as if every release could be a chemspill release, and designed our release automation accordingly.
This mindset has three important consequences:
Before the start of the release, one person is designated to assume responsibility for coordinating the entire release. This person needs to attend triage meetings, understand the background context on all the work being landed, referee bug severity disputes fairly, approve landing of late-breaking changes, and make tough back-out decisions. Additionally, on the actual release day this person is on point for all communications with the different groups (developers, QA, Release Engineering, website developers, PR, marketing, etc.).
Different companies use different titles for this role. Some titles we've heard include Release Manager, Release Engineer, Program Manager, Project Manager, Product Manager, Product Czar, Release Driver. In this chapter, we will use the term "Release Coordinator" as we feel it most clearly defines the role in our process as described above. The important point here is that the role, and the final authority of the role, is clearly understood by everyone before the release starts, regardless of their background or previous work experiences elsewhere. In the heat of a release day, it is important that everyone knows to abide by, and trust, the coordination decisions that this person makes.
The Release Coordinator is the only person outside of Release Engineering who is authorized to send "stop builds" emails if a show-stopper problem is discovered. Any reports of suspected show-stopper problems are redirected to the Release Coordinator, who will evaluate, make the final go/no-go decision and communicate that decision to everyone in a timely manner. In the heat of the moment of a release day, we all have to abide by, and trust, the coordination decisions that this person makes.
Early experiments with sending "go to build" in IRC channels or verbally over the phone led to misunderstandings, occasionally causing problems for the release in progress. Therefore, we now require that the "go to build" signal for every release is done by email, to a mailing list that includes everyone across all groups involved in release processes. The subject of the email includes "go to build" and the explicit product name and version number; for example:
go to build Firefox 6.0.1
Similarly, if a problem is found in the release, the Release Coordinator will send a new "all stop" email to the same mailing list, with a new subject line. We found that it was not sufficient to just hit reply on the most recent email about the release; email threading in some email clients caused some people to not notice the "all stop" email if it was way down a long and unrelated thread.
It is the role of the Release Coordinator to balance all the facts and opinions, reach a decision, and then communicate that decision about urgency consistently across all groups. If new information arrives, the Release Coordinator reassesses, and then communicates the new urgency to all the same groups. Having some groups believe a release is a chemspill, while other groups believe the same release is routine can be destructive to cross-group cohesion.
Finally, these emails also became very useful to measure where time was spent during a release. While they are only accurate to wall-clock time resolution, this accuracy is really helpful when figuring out where next to focus our efforts on making things faster. As the old adage goes, before you can improve something, you have to be able to measure it.
Throughout the beta cycle for Firefox we also do weekly releases from
our mozilla-beta
repository. Each
one of these beta releases goes through our usual full release
automation, and is treated almost identically to our regular final
releases. To minimize surprises during a release, our intent is to
have no new untested changes to release automation or
infrastructure by the time we start the final release builds.
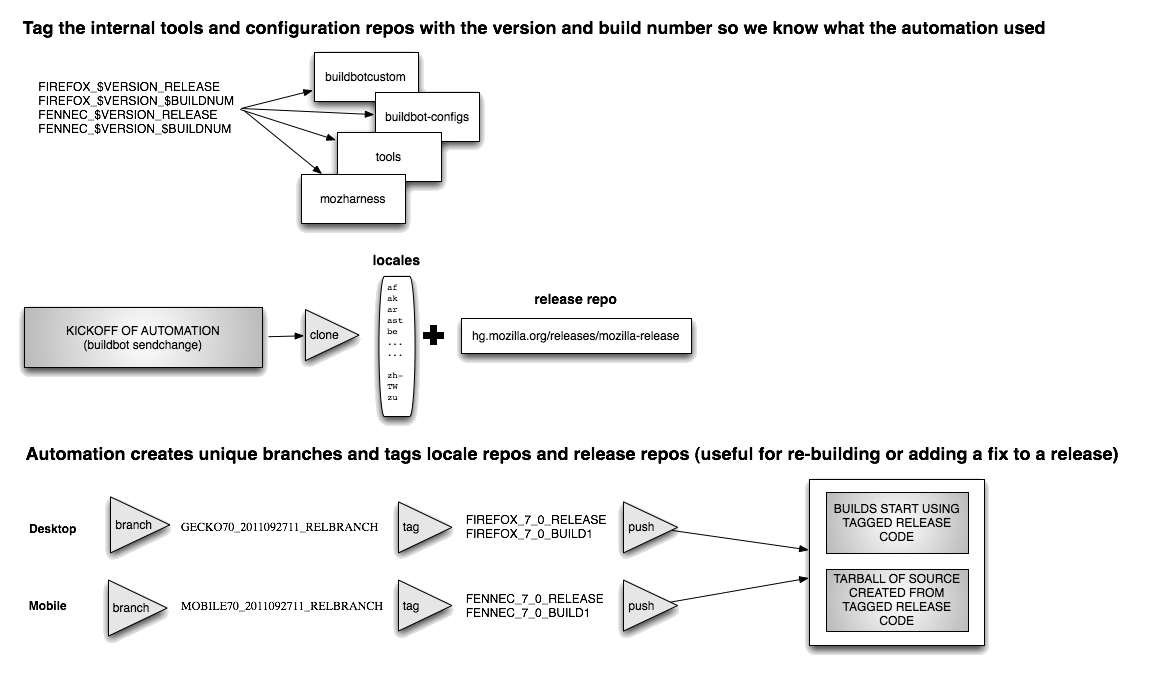
In preparation for starting automation, we recently started to use a
script,
release_sanity.py,
that was originally written by a Release Engineering summer intern. This
Python script assists a release engineer with double-checking that all
configurations for a release match what is checked into our tools and
configuration repositories. It also checks what is in the specified release
code revisions for mozilla-release and all the (human)
languages for this release, which will be what the builds and language
repacks are generated from.
The script accepts the buildbot config files for any release configurations
that will be used (such as desktop or mobile), the branch to look at (e.g.,
mozilla-release), the build and version number, and the names of the
products that are to be built (such as "fennec" or "firefox"). It will fail if
the release repositories do not
match what's in the configurations, if locale repository changesets don't
match our shipping locales and localization changeset files, or if the
release version and build number don't match what has been given to
our build tools with the tag generated using the product,
version, and build number. If all
the tests in the script pass, it will reconfigure the
buildbot master where the script is being run and where release
builders will be triggered, and then generate the "send change" that
starts the automated release process.
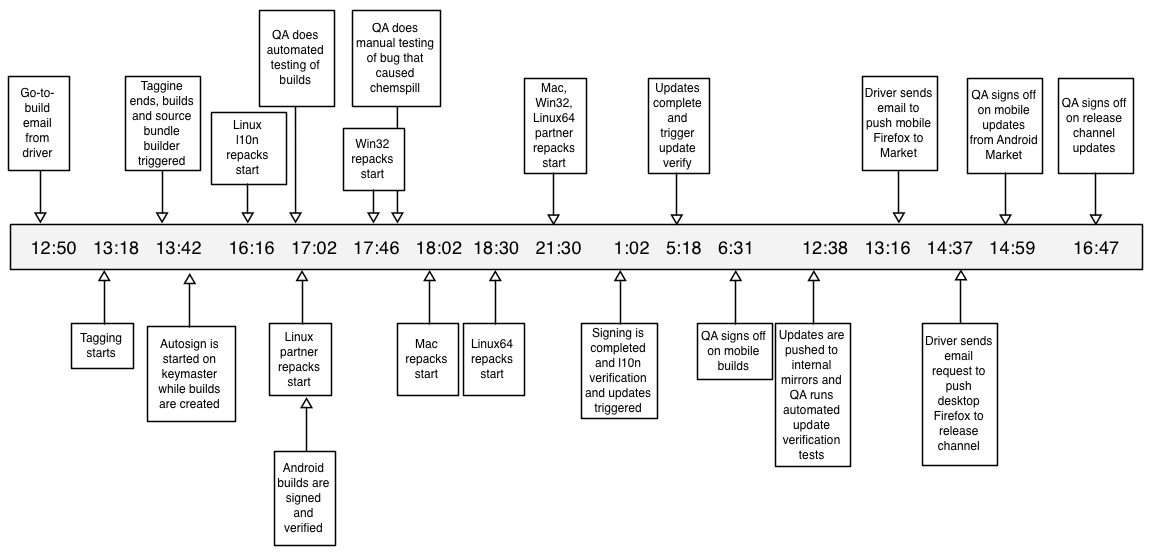
After a release engineer kicks off builders,
the first automated step in the Firefox release process is tagging all
the related source code repositories to record which revision of
the source, language repositories, and related tools are being used for this
version and build number of a release candidate.
These tags allow us
to keep a history of Firefox and Fennec (mobile Firefox) releases'
version and build numbers in our release repositories.
For Firefox releases, one example tag set is
FIREFOX_10_0_RELEASE FIREFOX_10_0_BUILD1 FENNEC_10_0_RELEASE FENNEC_10_0_BUILD1.
A single Firefox
release uses code from about 85 version control repositories that host
things such as the product code, localization strings, release
automation code, and helper utilities. Tagging all these repositories
is critical to ensure that future steps of the release
automation are all executed using the same set of revisions. It also has a
number of other benefits: Linux distributions and other contributors
can reproduce builds with exactly the same code and tools that go into the
official builds, and it also records the revisions of source and tools
used on a per-release basis for future comparison of what changed
between releases.
Once all the repositories are branched and tagged, a series of dependent builders
automatically start up: one builder for each release platform plus a
source bundle that includes all source used in the release. The source
bundle and built installers are all uploaded to the release directory
as they become available. This allows anyone to see exactly what code
is in a release, and gives a snapshot that would allow us to re-create
the builds if we ever needed to (for example, if our VCS failed somehow).
For the Firefox build's source, sometimes we need to import code
from an earlier repository. For example, with a beta release this means
pulling in the signed-off revision from Mozilla-Aurora (our
more-stable-than-Nightly repository) for Firefox 10.0b1. For a release it
means pulling in the approved changes from Mozilla-Beta (typically the
same code used for 10.0b6) to the Mozilla-Release repository. This release
branch is then created as a named branch whose parent changeset is
the signed-off revision from the `go to build' provided by the Release
Coordinator. The release branch can be used to make release-specific
modifications to the source code, such as bumping version numbers or
finalizing the set of locales that will be built. If a critical
security vulnerability is discovered in the future that requires an
immediate fix—a chemspill—a minimal set of changes to
address the vulnerability will be landed on this relbranch and a new
version of Firefox generated and released from it. When we have to do another round of
builds for a particular release, buildN, we use these relbranches to
grab the same code that was signed off on for `go to build', which is
where any changes to that release code will have been landed. The
automation starts again and bumps the tagging to the new changeset on
that relbranch.
Our tagging process does a lot of operations with local and
remote Mercurial repositories. To streamline some of the most
common operations we've written a few tools to assist us:
retry.py
and
hgtool.py.
retry.py is a simple wrapper that can take a given command and
run it, retrying several times if it fails. It can also watch for
exceptional output conditions and retry or report failure in those
cases. We've found it useful to wrap retry.py around most of the
commands which can fail due to external dependencies. For tagging,
the Mercurial operations could fail due to temporary network outages, web
server issues, or the backend Mercurial server being temporarily
overloaded. Being able to automatically retry these operations and
continue saves a lot of our time, since we don't have to manually
recover, clean up any fallout and then get the release automation running again.
hgtool.py is a utility that encapsulates several common Mercurial
operations, like cloning, pulling, and updating with a single invocation. It
also adds support for Mercurial's share extension, which we use extensively
to avoid having several full clones of repositories in
different directories on the same machine. Adding support for shared
local repositories significantly sped up our tagging process, since most
full clones of the product and locale repositories could be avoided.
An important motivation for developing tools like these is
making our automation as testable as possible. Because tools like
hgtool.py are small, single-purpose utilities built on top of
reusable libraries, they're much easier to test in isolation.
Today our tagging is done in two parallel jobs: one for desktop Firefox which takes around 20 minutes to complete as it includes tagging 80+ locale repositories, and another for mobile Firefox which takes around 10 minutes to complete since we have fewer locales currently available for our mobile releases. In the future we would like to streamline our release automation process so that we tag all the various repositories in parallel. The initial builds can be started as soon as the product code and tools requirement repository is tagged, without having to wait for all the locale repositories to be tagged. By the time these builds are finished, the rest of the repositories will have been tagged so that localization repackages and future steps can be completed. We estimate this can reduce the total time to have builds ready by 15 minutes.
Once the desktop builds are generated and uploaded to
ftp.mozilla.org, our automation triggers the localization
repackaging jobs. A "localization repack" takes the original
build (which contains the en-US locale), unpacks it, replaces
the en-US strings with the strings for another locale that we
are shipping in this release, then repackages all the files back
up again (this is why we call them repacks). We repeat this
for each locale shipping in the release. Originally, we did all
repacks serially. However, as we added more locales, this took
a long time to complete, and we had to restart from the beginning
if anything failed out mid-way through.
Now, we instead split the entire set of repacks into six jobs, each processed concurrently on six different machines. This approach completes the work in approximately a sixth of the time. This also allows us to redo a subset of repacks if an individual repack fails, without having to redo all repacks. (We could split the repacks into even more, smaller, concurrent jobs, but we found it took away too many machines from the pool, which affected other unrelated jobs triggered by developers on our continuous integration system.)
The process for mobile (on Android) is slightly different, as we produce
only two installers: an English version and a multi-locale version
with over a dozen languages built into the installer
instead of a separate build per locale. The size of this
multi-locale version is an issue, especially with slow
download speeds onto small mobile devices. One proposal for
the future is to have other languages be requested on demand
as add-ons from addons.mozilla.org.
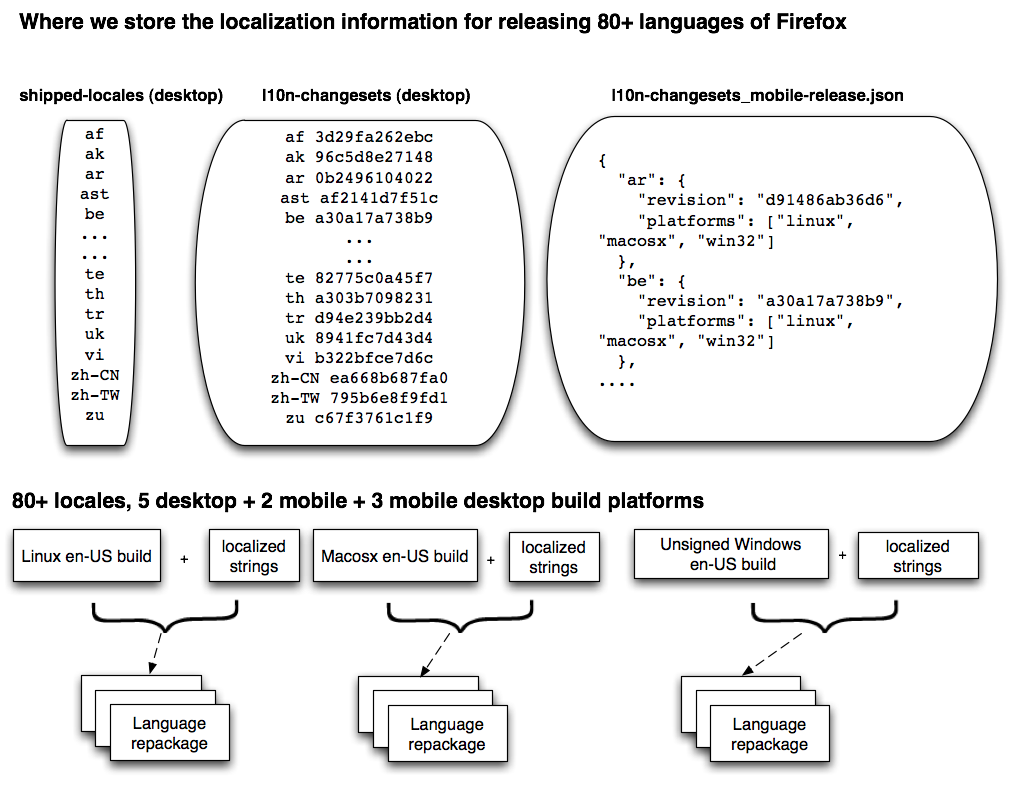
In Figure 2.4, you can see that we currently rely
on three different sources for our locale information:
shipped_locales, l10_changesets and
l10n-changesets_mobile-release.json. (There is a plan to move
all three into a unified JSON file.) These files contain information
about the different localizations we have, and certain platform
exceptions. Specifically, for a given localization we need to know
which revision of the repository to use for a given release and we
need to know if the localization can build on all of our supported
platforms (e.g., Japanese for Mac comes from a different repository all
together). Two of these files are used for the Desktop releases and
one for the Mobile release (this JSON file contains both the list of
platforms and the changesets).
Who decides which languages we ship? First of all, localizers themselves nominate their specific changeset for a given release. The nominated changeset gets reviewed by Mozilla's localization team and shows up in a web dashboard that lists the changesets needed for each language. The Release Coordinator reviews this before sending the "go to build" email. On the day of a release, we retrieve this list of changesets and we repackage them accordingly.
Besides localization repackages we also generate partner repackages. These are customized builds for various partners we have who want to customize the experience for their customers. The main type of changes are custom bookmarks, custom homepage and custom search engines but many other things can be changed. These customized builds are generated for the latest Firefox release and not for betas.
In order for users to be sure that the copy of Firefox they have downloaded is indeed the unmodified build from Mozilla, we apply a few different types of digital signatures to the builds.
The first type of signing is for our Windows builds. We use a
Microsoft Authenticode (signcode) signing key to sign all our
.exe and .dll files. Windows can use these signatures to
verify that the application comes from a trusted source. We also sign
the Firefox installer executable with the Authenticode key.
Next we use GPG to generate a set of MD5 and SHA1 checksums for all the builds on all platforms, and generate detached GPG signatures for the checksum files as well as all the builds and installers. These signatures are used by mirrors and other community members to validate their downloads.
For security purposes, we sign on a dedicated signing machine that is blocked off via firewall and VPN from outside connections. Our keyphrases, passwords, and keystores are passed among release engineers only in secure channels, often in person, to minimize the risk of exposure as much as possible.
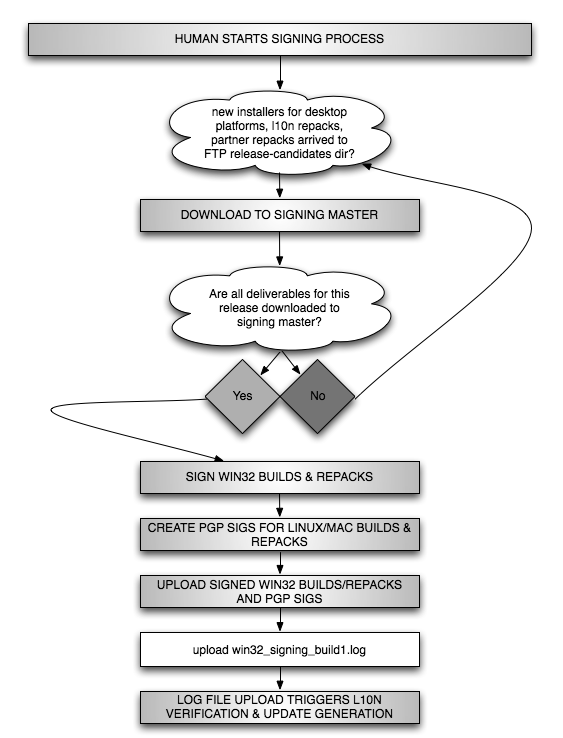
Until recently this signing process involved a release engineer
working on a dedicated server (the "signing master") for almost an
hour manually downloading builds, signing them, and
uploading them back to ftp.mozilla.org before the automation could
continue. Once signing on the master was completed and all files were
uploaded, a log file of all the signing activities was uploaded to
the release candidates directory on ftp.mozilla.org. The appearance
of this log file on ftp.mozilla.org signified the end of human signing
work and from that point, dependent builders watching for that log
file could resume automation. Recently we've added an additional
wrapper of automation around the signing steps. Now the release engineer
opens a Cygwin shell on the signing master
and sets up a few environment variables pertaining to the release, like
VERSION, BUILD, TAG, and RELEASE_CONFIG, that
help the script find the right directories on ftp.mozilla.org and know
when all the deliverables for a release have been downloaded so that
the signing can start. After checking out the most recent production
version of our signing tools, the release engineer simply runs
make autosign. The release engineer then enters two
passphrases, one for gpg and one for signcode. Once these passphrases
are automatically verified by the make scripts, the automation
starts a download loop that watches for uploaded builds and repacks
from the release automation and downloads them as they become
available. Once all items have been downloaded, the automation
begins signing immediately, without human intervention.
Not needing a human to sign is important for two reasons. Firstly, it reduces the risk of human error. Secondly, it allows signing to proceed during non-work hours, without needing a release engineer awake at a computer at the time.
All deliverables have an MD5SUM and SHA1SUM generated for them, and
those hash values are written to files of the same name. These files
will be uploaded back to the release-candidates directory as well as
synced into the final location of the release on ftp.mozilla.org once
it is live, so that anyone who downloads a Firefox installer from one of our
mirrors can ensure they got the correct object. When all signed bits
are available and verified
they are uploaded back to ftp.mozilla.org along
with the signing log file, which the automation is waiting for to
proceed.
Our next planned round of improvements to the signing process will create a tool that allows us to sign bits at the time of build/repack. This work requires creating a signing server application that can receive requests to sign files from the release build machines. It will also require a signing client tool which would contact the signing server, authenticate itself as a machine trusted to request signing, upload the files to be signed, wait for the build to be signed, download the signed bits, and then include them as part of the packaged build. Once these enhancements are in production, we can discontinue our current all-at-once signing process, as well as our all-at-once generate-updates process (more on this below). We expect this work to trim a few hours off our current end-to-end times for a release.
Updates are created so users can update to the latest version of Firefox quickly and easily using our built-in updater, without having to download and run a standalone installer. From the user's perspective, the downloading of the update package happens quietly in the background. Only after the update files are downloaded, and ready to be applied, will Firefox prompt the user with the option to apply the update and restart.
The catch is, we generate a lot of updates. For a series of releases on
a product line, we generate updates from all supported previous releases in the
series to the new latest release for that product line. For Firefox
LATEST, that means generating updates for every platform, every locale,
and every installer from Firefox LATEST-1, LATEST-2,
LATEST-3, … in both complete and partial forms. We do all this
for several different product lines at a time.
Our update generation automation modifies the update configuration files
of each release's build off a branch to maintain our canonical list of
what version numbers, platforms, and localizations need to have
updates created to offer users this newest release. We offer updates
as "snippets". As you can see in the example below, this snippet is
simply an XML pointer file hosted on our AUS (Application Update
Service) that informs the user's Firefox browser where the complete
and/or partial .mar (Mozilla Archive) files are hosted.
<updates>
<update type="minor" version="7.0.1" extensionVersion="7.0.1"
buildID="20110928134238"
detailsURL="https://www.mozilla.com/en-US/firefox/7.0.1/releasenotes/">
<patch type="complete"
URL="http://download.mozilla.org/?product=firefox-7.0.1-complete&os=osx&lang=en-US&force=1"
hashFunction="SHA512"
hashValue="7ecdbc110468b9b4627299794d793874436353dc36c80151550b08830f9d8c5afd7940c51df9270d54e11fd99806f41368c0f88721fa17e01ea959144f473f9d"
size="28680122"/>
<patch type="partial"
URL="http://download.mozilla.org/?product=firefox-7.0.1-partial-6.0.2&os=osx&lang=en-US&force=1"
hashFunction="SHA512"
hashValue="e9bb49bee862c7a8000de6508d006edf29778b5dbede4deaf3cfa05c22521fc775da126f5057621960d327615b5186b27d75a378b00981394716e93fc5cca11a"
size="10469801"/>
</update>
</updates>
As you can see in Figure 2.6, update snippets
have a type attribute which can be either major or
minor.
Minor updates keep people updated to the latest version
available in their release train; for example, it would update all
3.6.* release users to the latest 3.6 release, all rapid-release beta
users to the latest beta, all Nightly users to the
latest Nightly build, etc. Most of the time, updates are minor and
don't require any user interaction other than a confirmation to apply the
update and restart the browser.
Major updates are used when we need to advertise to our users that the latest and greatest release is available, prompting them that "A new version of Firefox is available, would you like to update?" and displaying a billboard showcasing the leading features in the new release. Our new rapid-release system means we no longer need to do as many major updates; we'll be able to stop generating major updates once the 3.6.* release train is no longer supported.
At build time we generate "complete update" .mar files which
contain all the files for the new release, compressed with bz2
and then archived into a .mar file. Both complete and partial
updates are downloaded automatically through the update channel to which a
user's Firefox is registered. We have different update channels (that is,
release users look
for updates on release channel, beta users look on beta channel, etc.) so that
we can serve updates to, for example, release users at a different time than
we serve updates to beta users.
Partial update .mar files are created by comparing the complete .mar for the
old release with the complete .mar for the new release to create a
"partial-update" .mar file containing the binary diff of any
changed files, and a manifest file. As you can see in the sample
snippet in Figure 2.6, this results in a much smaller file size for partial
updates. This is very important for users with slower or
dial-up Internet connections.
In older versions of our update automation the generation of partial updates for all locales and platforms could take six to seven hours for one release, as the complete .mar files were downloaded, diffed, and packaged into a partial-update .mar file. Eventually it was discovered that even across platforms, many component changes were identical, therefore many diffs could be re-used. With a script that cached the hash for each part of the diff, our partial update creation time was brought down to approximately 40 minutes.
After the snippets are uploaded and are hosted on AUS, an update verification step is run to a) test downloading the snippets and b) run the updater with the downloaded .mar file to confirm that the updates apply correctly.
Generation of partial-update .mar files, as well as all the update snippets, is currently done after signing is complete. We do this because generation of the partial updates must be done between signed files of the two releases, and therefore generation of the snippets must wait until the signed builds are available. Once we're able to integrate signing into the build process, we can generate partial updates immediately after completing a build or repack. Together with improvements to our AUS software, this means that once we're finished builds and repacks we would be able to push immediately to mirrors. This effectively parallelizes the creation of all the updates, trimming several hours from our total time.
Verifying that the release process is producing the expected deliverables is key. This is accomplished by QA's verification and sign offs process.
Once the signed builds are available, QA starts manual and automated testing. QA relies on a mix of community members, contractors and employees in different timezones to speed up this verification process. Meanwhile, our release automation generates updates for all languages and all platforms, for all supported releases. These update snippets are typically ready before QA has finished verifying the signed builds. QA then verifies that users can safely update from various previous releases to the newest release using these updates.
Mechanically, our automation pushes the binaries to our "internal
mirrors" (Mozilla-hosted servers) in order for QA to verify
updates. Only after QA has finished verification of the builds and
the updates will we push them to our
community mirrors. These community mirrors are essential to
handle the global load of users, by allowing them to request their updates
from local mirror nodes instead of from ftp.mozilla.org
directly. It's worth noting that we do not make builds and updates
available on the community mirrors until after QA signoff, because of
complications that arise if QA finds a last-minute showstopper
and the candidate build needs to be withdrawn.
The validation process after builds and updates are generated is:
Note that users don't get updates until QA has signed off and the Release Coordinator has sent the email asking to push the builds and updates live.
Once the Release Coordinator gets signoff from QA and various other groups at Mozilla, they give Release Engineering the go-ahead to push the files to our community mirror network. We rely on our community mirrors to be able to handle a few hundred million users downloading updates over the next few days. All the installers, as well as the complete and partial updates for all platforms and locales, are already on our internal mirror network at this point. Publishing the files to our external mirrors involves making a change to an rsync exclude file for the public mirrors module. Once this change is made, the mirrors will start to synchronize the new release files. Each mirror has a score or weighting associated with it; we monitor which mirrors have synchronized the files and sum their individual scores to compute a total "uptake" score. Once a certain uptake threshold is reached, we notify the Release Coordinator that the mirrors have enough uptake to handle the release.
This is the point at which the release becomes "official". After the Release Coordinator sends the final "go live" email, Release Engineering will update the symlinks on the web server so that visitors to our web and ftp sites can find the latest new version of Firefox. We also publish all the update snippets for users on past versions of Firefox to AUS.
Firefox installed on users' machines regularly checks our AUS servers to see if there's an updated version of Firefox available for them. Once we publish these update snippets, users are able to automatically update Firefox to the latest version.
As software engineers, our temptation is to jump to solve what we see as the immediate and obvious technical problem. However, Release Engineering spans across different fields—both technical and non-technical—so being aware of technical and non-technical issues is important.
It was important to make sure that all stakeholders understood that our slow, fragile release engineering exposed the organization, and our users, to risks. This involved all levels of the organization acknowledging the lost business opportunities, and market risks, caused by slow fragile automation. Further, Mozilla's ability to protect our users with super-fast turnaround on releases became more important as we grew to have more users, which in turn made us more attractive as a target.
Interestingly, some people had only ever experienced fragile release automation in their careers, so came to Mozilla with low, "oh, it's always this bad" expectations. Explaining the business gains expected with a robust, scalable release automation process helped everyone understand the importance of the "invisible" Release Engineering improvement work we were about to undertake.
To make the release process more efficient and more reliable required work, by Release Engineering and other groups across Mozilla. However, it was interesting to see how often "it takes a long time to ship a release" was mistranslated as "it takes Release Engineering a long time to ship a release". This misconception ignored the release work done by groups outside of Release Engineering, and was demotivating to the Release Engineers. Fixing this misconception required educating people across Mozilla on where time was actually spent by different groups during a release. We did this with low-tech "wall-clock" timestamps on emails of clear handoffs across groups, and a series of "wall-clock" blog posts detailing where time was spent.
Many of our "release engineering" problems were actually people problems: miscommunication between teams; lack of clear leadership; and the resulting stress, fatigue and anxiety during chemspill releases. By having clear handoffs to eliminate these human miscommunications, our releases immediately started to go more smoothly, and cross-group human interactions quickly improved.
When we started this project, we were losing team members too often. In itself, this is bad. However, the lack of accurate up-to-date documentation meant that most of the technical understanding of the release process was documented by folklore and oral histories, which we lost whenever a person left. We needed to turn this situation around, urgently.
We felt the best way to improve morale and show that things were getting better was to make sure people could see that we had a plan to make things better, and that people had some control over their own destiny. We did this by making sure that we set aside time to fix at least one thing—anything!—after each release. We implemented this by negotiating for a day or two of "do not disturb" time immediately after we shipped a release. Solving immediate small problems, while they were still fresh in people's minds, helped clear distractions, so people could focus on larger term problems in subsequent releases. More importantly, this gave people the feeling that we had regained some control over our own fate, and that things were truly getting better.
Because of market pressures, Mozilla's business and product needs from the release process changed while we were working on improving it. This is not unusual and should be expected.
We knew we had to continue shipping releases using the current release process, while we were building the new process. We decided against attempting to build a separate "greenfield project" while also supporting the existing systems; we felt the current systems were so fragile that we literally would not have the time to do anything new.
We also assumed from the outset that we didn't fully understand what was broken. Each incremental improvement allowed us to step back and check for new surprises, before starting work on the next improvement. Phrases like "draining the swamp", "peeling the onion", and "how did this ever work?" were heard frequently whenever we discovered new surprises throughout this project.
Given all this, we decided to make lots of small, continuous improvements to the existing process. Each iterative improvement made the next release a little bit better. More importantly, each improvement freed up just a little bit more time during the next release, which allowed a release engineer a little more time to make the next improvement. These improvements snowballed until we found ourselves past the tipping point, and able to make time to work on significant major improvements. At that point, the gains from release optimizations really kicked in.
We're really proud of the work done so far, and the abilities that it has brought to Mozilla in a newly heated-up global browser market.
Four years ago, doing two chemspill releases in a month would be a talking point within Mozilla. By contrast, last week a published exploit in a third-party library caused Mozilla to ship eight chemspills releases in two low-fuss days.
As with everything, our release automation still has plenty of room for improvement, and our needs and demands continue to change. For a look at our ongoing work, please see: